开发积薪的技术架构
从设计到后端,我的第一个全栈项目

积薪是一个跟同类型产品不太一样的独立博客导航站,数据的抓取和分类自动进行,但也有人工的精选推荐。希望在这个写作和阅读长文都变成稀缺技能的年代,能给作者和读者搭建起一个流量通道。关于积薪更感性的介绍和更文艺的表达,请访问《依然相信文字的力量:独立博客导航站“积薪”正式发布》,本文主要介绍网站的技术架构。背景
我在学完Node.js入门教程后就希望一个人独立做一个完整的后端项目,克服对后端的恐惧——因为调试不直观,并对后端开发有个整体认识。此前我用Node.js做过一个获取图片EXIF并返回的接口,并已经在我的博客上运行了很久。但这毕竟是个极其简单的项目,仅仅是用Express做了路由,提取信息,返回信息。尽管后来增加了读写数据库,但也还是一个小工具,不是一个真正的后端项目。关于这个项目的介绍,请访问《Fetch EXIF升级了》和《利用ChatGPT实现一个Node.js API》。独立博客导航站是个我一直都有的想法,而且就复杂度而言很适合入门。有自动执行的爬虫任务,有数据库的增删改查。后续还可以加更多的功能。后端
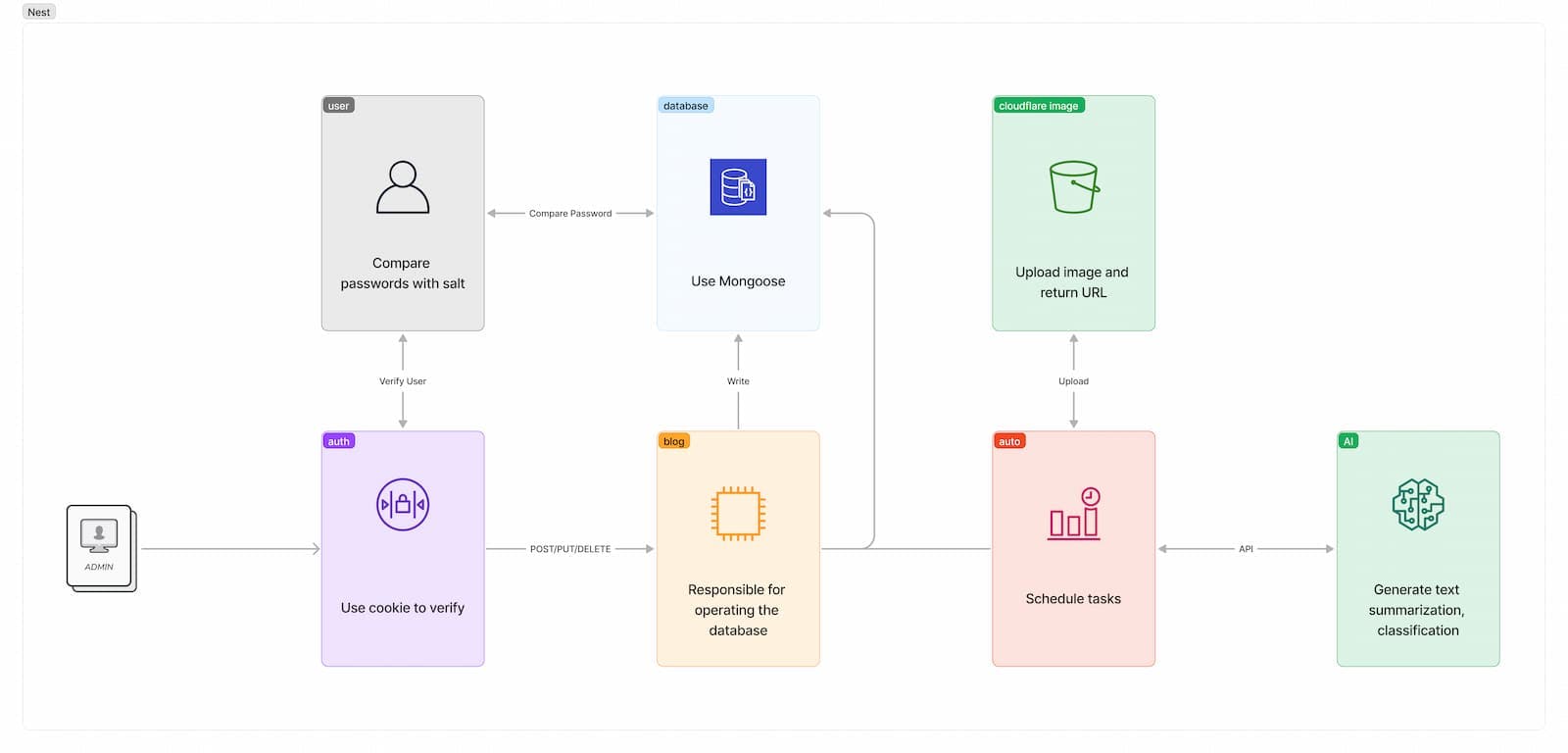
后端我选择了Node技术栈,框架使用的是Nest.js。Nest集成了很多实用的模块,跟数据库的交互、认证和鉴权都可以很轻松地处理。并且Nest的文档很详实,这一点很重要。积薪的后端分为几个Module:blog、auto、auth、user。auth和user负责用户的注册、登录,以及负责保护那些需要授权的接口——就是数据的增删改。blog包含两个controller:article和website。顾名思义,就是负责增删改查文章及博客的数据。auto是定时任务,负责定期抓取文章的更新,检测可访问性,统计数据。抓取依据是RSS文件。如果发现了数据库里没有的文章,会将文章数据抽取出来,进行一系列处理,最后存入数据库。因为数据库使用MongoDB,文章和网站之间并没有强关联。所以将每篇文章的访问量汇总计算是每天定时进行,而不是实时的。大部分独立博客的生命力并不持久,所以后端每个月会对所有文章进行一次可访问性检测,并对失联网页进行标记。后续版本会增加失效文章的显示。AI
如果仅仅将信息抓取来直接展示是一种很低效的方式,毕竟每个人感兴趣的内容不同。所以我用了百度的API将抓取的文章进行分类、打标签、整理摘要。你在首页上看到的标签、分类信息就是自动完成的。前端
这次我刻意没有使用更熟悉的React,而是采用目前前端界口碑很好的SvelteKit,逼自己学一下新框架。Svelte基本没有运行时,所以最终打包不会出现一大堆js文件。同时它的reactivity特性使我不需要写类似useState()的方法。但Svelte的缺点很明显, 首先是生态远不如React,另外文档和资料不够多。不管是在处理认证还是部署等方面,都没有太多现成的参考资料。都得你亲自从零造轮子。前端结构相对来说就很简单了。除了访客能看到的部分,还有一个需要登录才能访问的管理后台。部署
Nest.js和MongoDB通过Docker Compose在一台服务器上启动并且对外提供接口,前端通过Cloudflare Pages部署。本来Svelte跟Nest.js在同一个服务器运行,DNS解析也放在DNSpod。直到前几天收到一封邮件,DNSpod告诉我因为存在违规内容给我停止解析了。我索性把DNS解析和前端都放到Cloudflare了,不再考虑大陆访客。性能优化
前端的优化大多是Cloudflare提供的,主要是缓存。短时间内的大量访问并不会请求到后端,降低了后端的压力。积薪是一个100% SSR的网站,即使是接口,也是通过API Route进行而二次封装,用户端的请求也不会暴露后端URL。抓取频率是在白天4小时进行一次,也就是说数据更新不会太频繁。如果每一次访问都需要请求接口,会对服务器造成比较大的压力。所以我通过在Svelte的hooks.server.ts中设置了一个缓存逻辑。这个文件会处理所有Svelte收到的请求。如果将请求处理一下,把数据缓存到Redis,对于大部分访问来说不就不需要访问后端了吗?本来我都把这个功能做完了,结果发现了新问题:假如有人访问了第一页,这时候数据缓存到redis;然后数据更新了;第二个人访问第一页,这时候读的是缓存,访问第二页,是更新后的数据。这就导致第二个访客在两个页面中看到的可能有重复数据。虽然也是有办法解决,但后来因为上了Cloudflare,这个redis缓存就没有什么必要了。感受
亲自做一遍项目才会对各流程有更深入的认识,后端开发的思路就跟前端差别很大。在之前只敢做一些不依赖后端的简单项目,现在哪怕没有专业后端支持,咱也不怵了,大不了自己慢慢搞。 评论