From design to backend, my first full-stack project
2023年5月30日
本文共有1111字,预计阅读时间5分钟
Firewood is an independent blog navigation site that is different from other products of the same type. Data capture and classification are performed automatically, but there are also manual selection recommendations. I hope that in this era when writing and reading long articles have become scarce skills, a traffic channel can be built for authors and readers.For a more emotional introduction and more artistic expression of Firewood, please visit "Still Believe in the Power of Words: The Official Release of the Independent Blog Navigation Station 'Firewood'". This article mainly introduces the technical architecture of the website.
Background
After I finished the Node.js introductory tutorial, I hoped to do a complete back-end project independently, overcome the fear of the back-end-because debugging is not intuitive, and have an overall understanding of the back-end development.Before that, I used Node.js to make an interface to get the EXIF of the picture and return it, and it has been running on my blog for a long time. But this is an extremely simple project after all, just use Express to do routing, extract information, and return information. Although the read-write database was added later, it is still a small tool, not a real back-end project. For an introduction to this project, please visit "Fetch EXIF Upgraded" and "Implement a Node.js API using ChatGPT".A independent blog navigator is an idea I've always had, and it's a good entry in terms of complexity. There are crawler tasks that are automatically executed, and database additions, deletions, modifications, and queries. More functions can be added in the future.
Backend
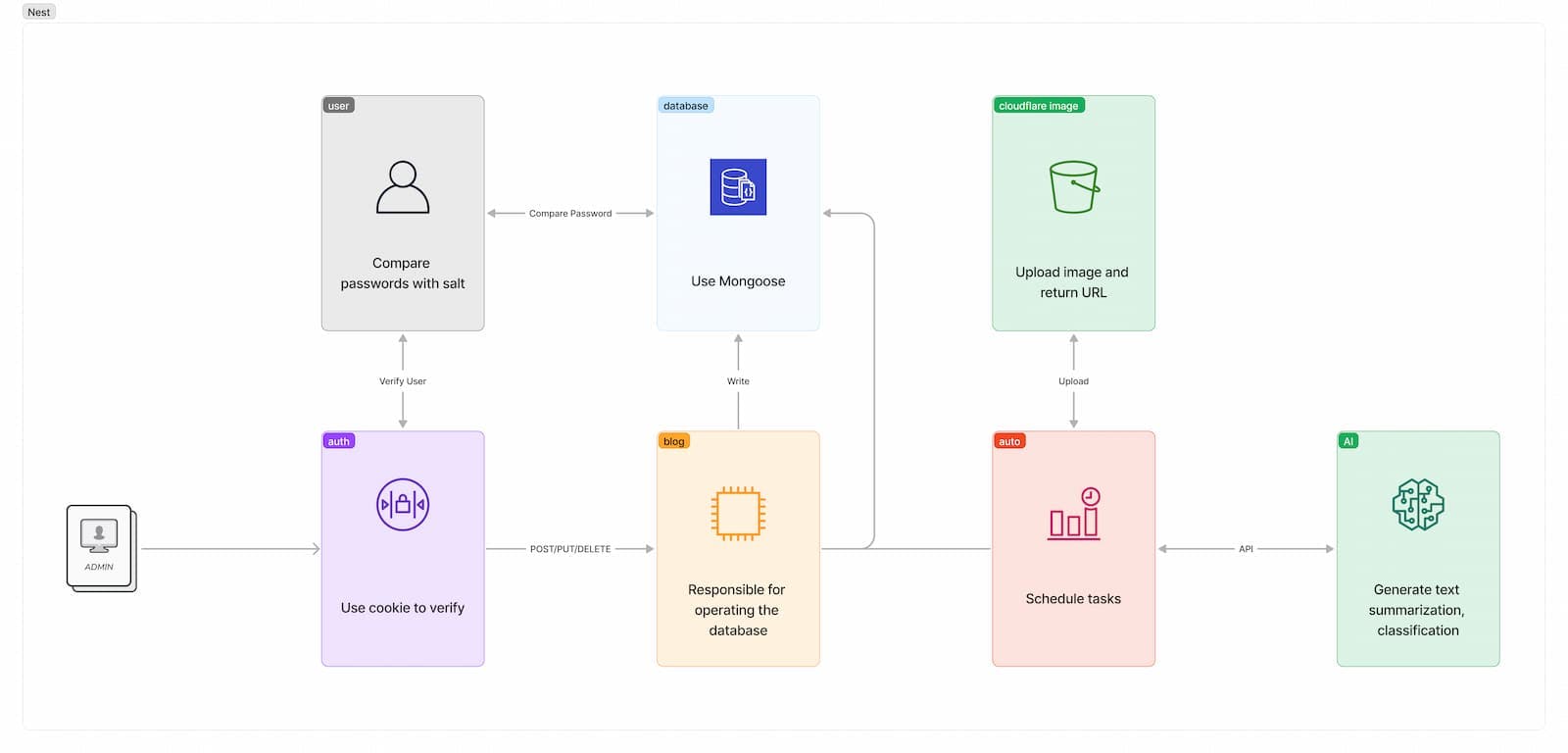
I chose the Node technology stack for the backend, and the framework uses Nest.js.Nest integrates many useful modules, and the interaction with the database, authentication and authentication can be easily handled. And Nest's documentation is solid, which is important.
The backend of the Firewood is divided into several modules: blog, auto, auth, user.Auth and user are responsible for user registration and login, and are responsible for protecting those interfaces that require authorization—that is, adding, deleting, and modifying data.The blog contains two controllers: article and website. As the name suggests, it is responsible for adding, deleting, modifying and checking the data of articles and blogs.Auto is a scheduled task, which is responsible for regularly grabbing article updates, detecting accessibility, and statistical data.Crawl is based on RSS files. If an article that is not in the database is found, the article data will be extracted, subjected to a series of processing, and finally stored in the database.Because the database uses MongoDB, there is no strong relationship between articles and websites. Therefore, the summary calculation of the visits of each article is performed on a regular basis every day, not in real time.The vitality of most independent blogs is not long-lasting, so the backend will check the accessibility of all articles every month and mark the missing webpages. Subsequent versions will increase the display of invalid articles.
AI
It is a very inefficient way to just capture information and display it directly, after all, everyone is interested in different content. So I used Baidu's API to classify, tag, and summarize the captured articles. The tags and category information you see on the home page are automatically completed.
Frontend
This time I deliberately did not use the more familiar React, but adopted SvelteKit, which has a good reputation in the front-end industry, to force myself to learn a new framework.Svelte basically has no runtime, so there will not be a lot of js files in the final package. At the same time, its reactivity feature makes me not need to write methods like useState().But the shortcomings of Svelte are obvious. First, the ecology is far inferior to React, and there are not enough documents and materials. Whether it's dealing with authentication, deployment, etc., there aren't many references out there. You have to build the wheel from scratch yourself.The front-end structure is relatively simple. In addition to the part that visitors can see, there is also an admin background that requires login to access.
Devops
Nest.js and MongoDB are started on a server through Docker Compose and provide external interfaces, and the front end is deployed through Cloudflare Pages.Originally, Svelte and Nest.js were running on the same server, and DNS resolution was also placed on DNSpod. Until I received an email a few days ago, DNSpod told me that it stopped parsing because of illegal content.I simply put the DNS resolution and front-end on Cloudflare, and no longer consider mainland visitors.
Performance optimization
Most of the front-end optimization is provided by Cloudflare, mainly caching. A large number of accesses in a short period of time will not be requested to the backend, reducing the pressure on the backend.I have also done an optimization before that is worth mentioning.Firewood is a 100% SSR website. Even the interface is re-encapsulated through API Route, and the user's request will not expose the back-end URL.The frequency of crawling is once every 4 hours during the day, which means that the data will not be updated too frequently. If every access needs to request an interface, it will put a lot of pressure on the server.So I set up a caching logic in Svelte's hooks.server.ts. This file will handle all requests Svelte receives. If the request is processed and the data is cached in Redis, wouldn't it be unnecessary to access the backend for most access?Originally, I finished this function, but found a new problem: if someone visits the first page, the data is cached in redis at this time; then the data is updated; the second person visits the first page, and the cache is read at this time. Access to the second page is the updated data.This leads to the possibility that the second visitor sees duplicate data on both pages. Although there is a solution, but because of Cloudflare, the redis cache is no longer necessary.
Feelings
Only by doing the project in person will you have a deeper understanding of each process. The idea of back-end development is very different from that of the front-end. In the past, I only dared to do some simple projects that did not rely on the backend. Now even if there is no professional backend support, we don’t have to worry about it. The big deal is to do it slowly.